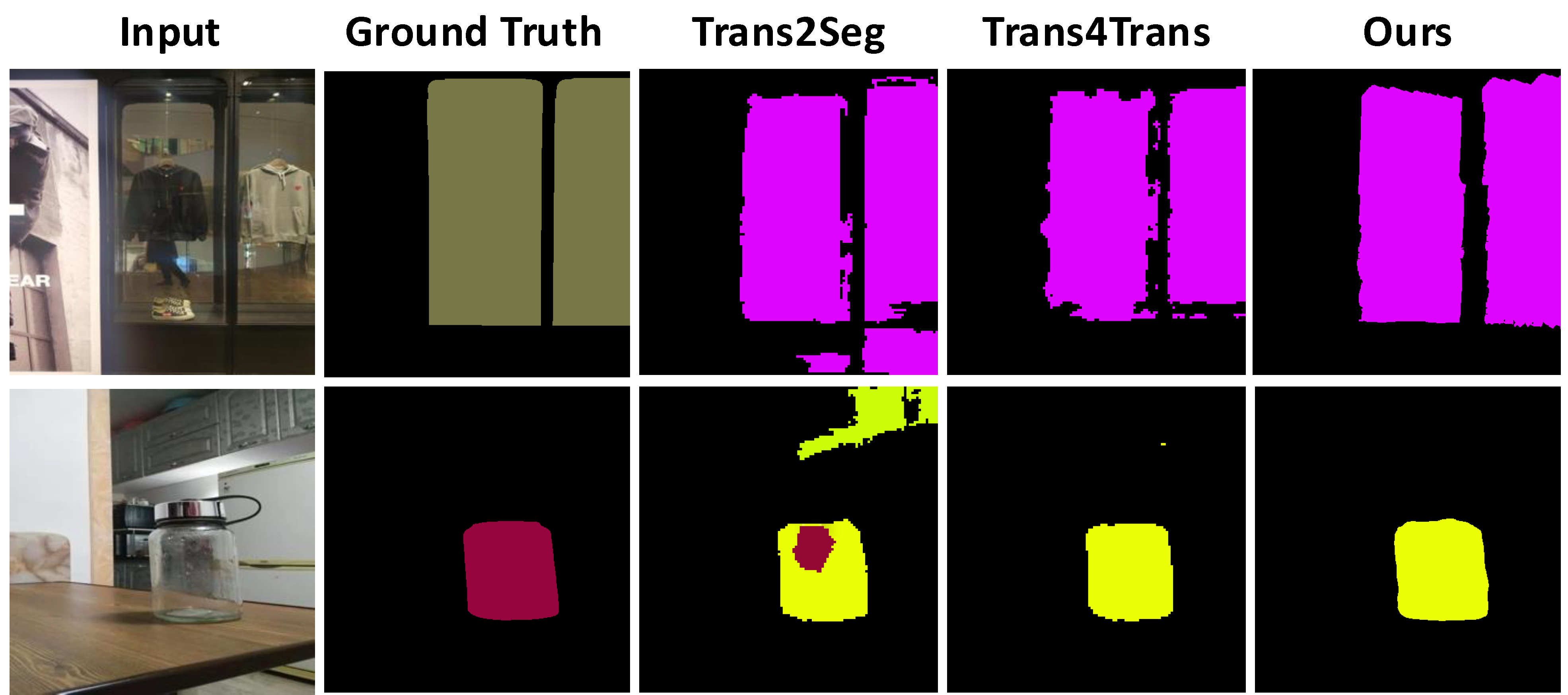
Method
TransCues Architecture
An encoder-decoder pyramid transformer where BFE and RFE modules are placed at the end of the decoder — empirically the optimal placement — to capture boundary then reflection cues in sequence before final MLP prediction.
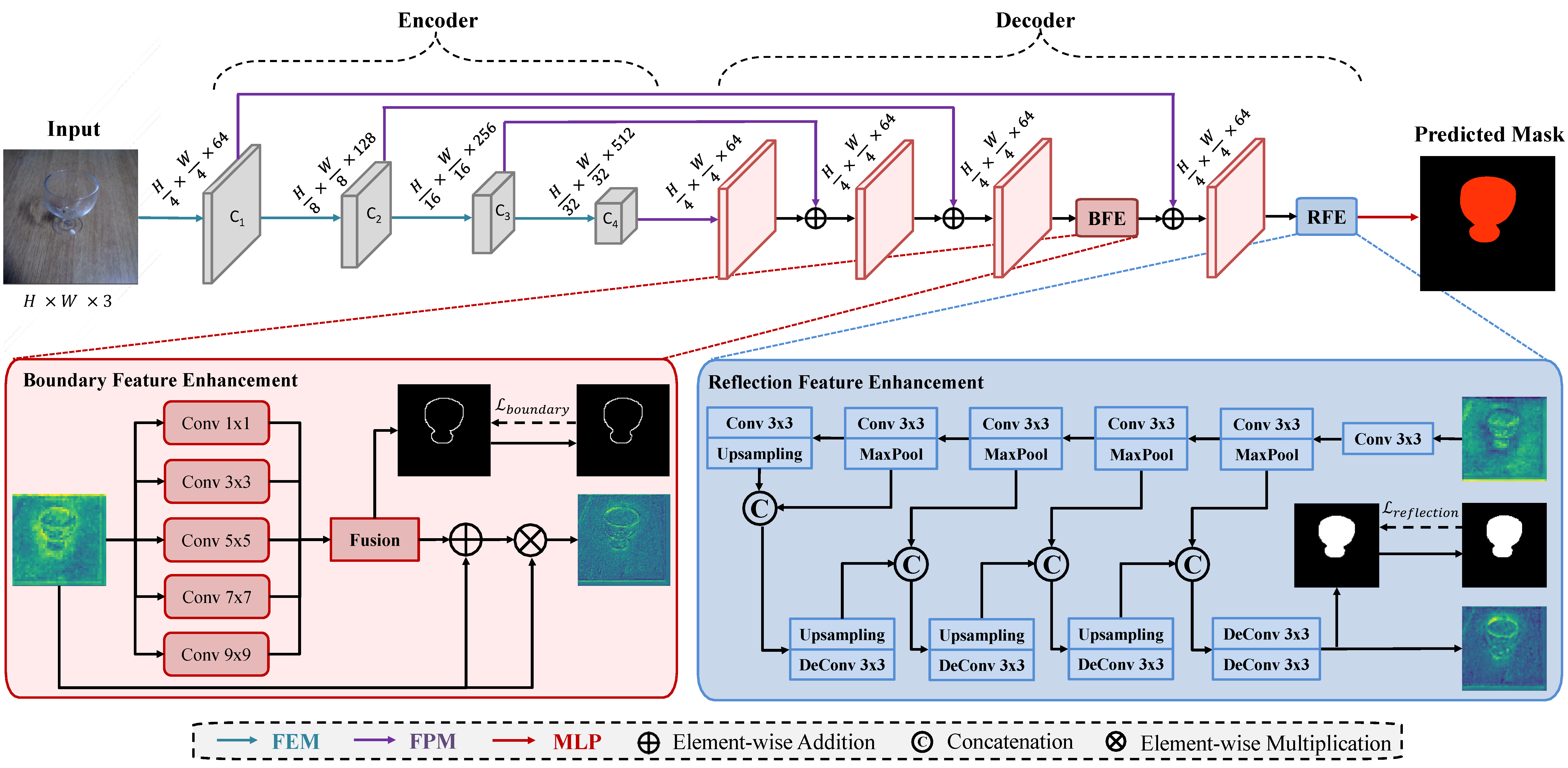
Feature Extraction Module
PVT-based encoder that captures multi-scale long-range dependencies. Four stages output feature maps at 1/4, 1/8, 1/16, and 1/32 resolution.
Feature Parsing Module
Lightweight decoder alternative to FEM. Captures detailed-to-abstract representations of transparent objects across C1–C4 with minimal parameters.
Boundary Feature Enhancement
Parallel convolution blocks (1×1 to 9×9) fused via an ASPP-inspired fusion module. Supervised by a Sobel-based boundary loss on gradient alignment.
Reflection Feature Enhancement
Conv-deconv U-Net that detects localised reflections. Uses pseudo ground-truth for reflective categories (windows, cups, bottles) for supervision.